创艺学院科研团队聚焦设计、制造与人工智能交叉领域的创新与实践,致力于打造创意驱动的科研实践新模式,形成深度学习、强化学习、生成模型、边缘计算等人工智能技术与智能设计、娱乐设计、构筑材料设计、增材制造、数字仿真、自动化检测与控制相融合的科研实践平台。2024年2月,武颖娜、田政课题组的科研成果同时被IEEE 举办的计算机视觉及人工智能领域顶级学术会议CVPR (IEEE Conference on Computer Vision and Pattern Recognition)接收。
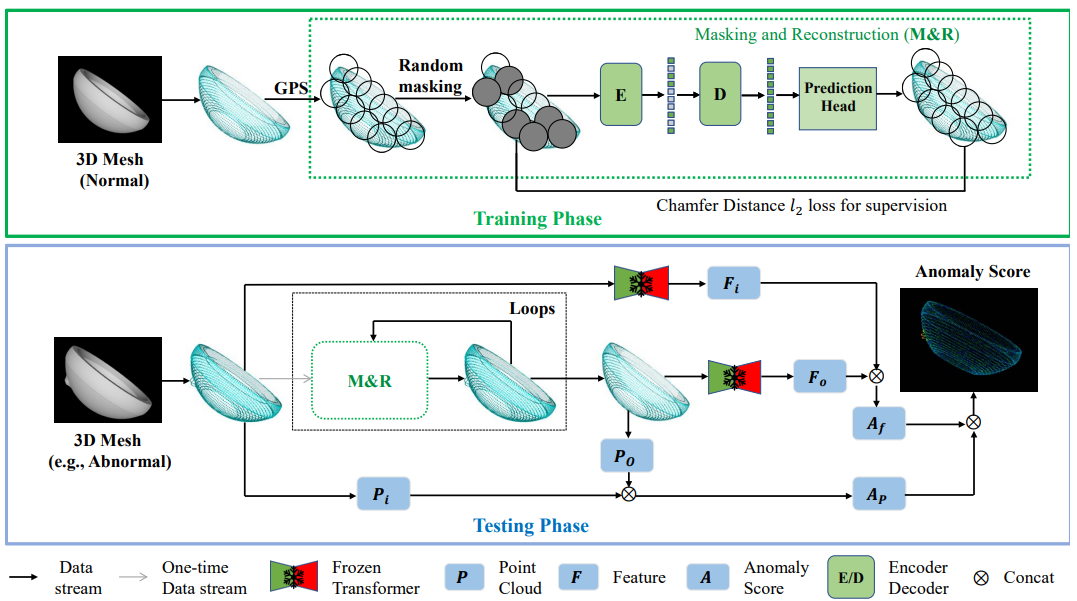
针对制造业产品表面质量检测的自动化、智能化需求,智造系统工程中心(CASE)武颖娜课题组致力于开发应用于工业场景的异常检测视觉算法与系统。为了解决异常检测过程中,工业相机采样的二维图像无法完全捕捉缺陷信息的问题,课题组提出了一种全新的三维异常生成以及检测方法。在现有的ShapeNet数据集上,采用python API、blender构造多类异常模型,生成了多样化的Anomaly ShapeNet三维异常检测数据集。为了精准识别与定位三维点云模型中的异常,课题组提出了基于迭代自监督掩码重建的IMRNet异常检测算法,与目前的三维异常检测算法相比,检出率明显提升。该研究成果以“Towards Scalable 3D Anomaly Detection and Localization: A Benchmark via 3D Anomaly Synthesis and A Self-Supervised Learning Network”为题被CVPR 2024会议接收。上海科技大学为该成果的第一完成单位,CASE的2022级硕士研究生李文峤为第一作者,武颖娜与信息学院高盛华为共同通讯作者,论文合作者中还包括密歇根州立大学安娜堡分校的徐晓豪、CASE 2023级硕士研究生谷峣、郑博中。arxiv链接: https://arxiv.org/abs/2311.14897
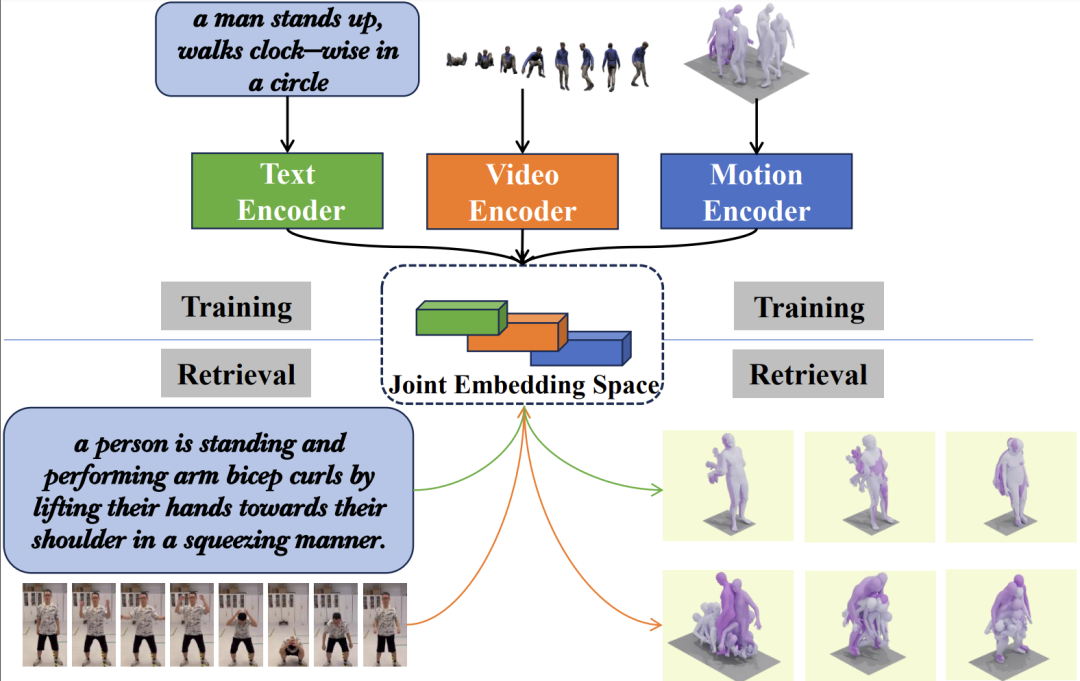
用于人体运动检索的三模态学习框架
人体运动数据检索任务在娱乐设计中有着广泛的应用潜力。以往的研究主要聚焦于双模态学习,例如将文本数据与运动数据结合的任务,而对于融合三种模态的学习探索较少。直观上,加入一个额外的模态不仅能扩展模型的应用范围,更关键的是,如果选取合适的额外模态,它还可以作为一个桥梁,加强其他两种不同模态之间的相互对齐。针对这一点,人工智能与数字艺术实验室(AIDA)田政课题组提出了一个创新的语言-视频-运动三模态学习框架。该框架通过引入以人为中心的视频作为额外模态,有效地促进了文本和运动之间的联系。实验结果显示,在HumanML3D和KIT-ML数据集上,该三模态框架在包括文本到运动、运动到文本、视频到运动和运动到视频等多种与运动相关的跨模态检索任务中,实现了当前最好的性能。该研究成果以“Tri-Modal Motion Retrieval by Learning a Joint Embedding Space”为题被CVPR 2024会议接收。上海科技大学为该成果的第一完成单位,AIDA的2022级硕士研究生殷康宁为第一作者,田政为通讯作者,论文合作者中还包括中科院深圳先进技术研究院的邹诗浩、AIDA 2023级硕士研究生葛宇轩。arxiv链接: https://arxiv.org/abs/2403.00691
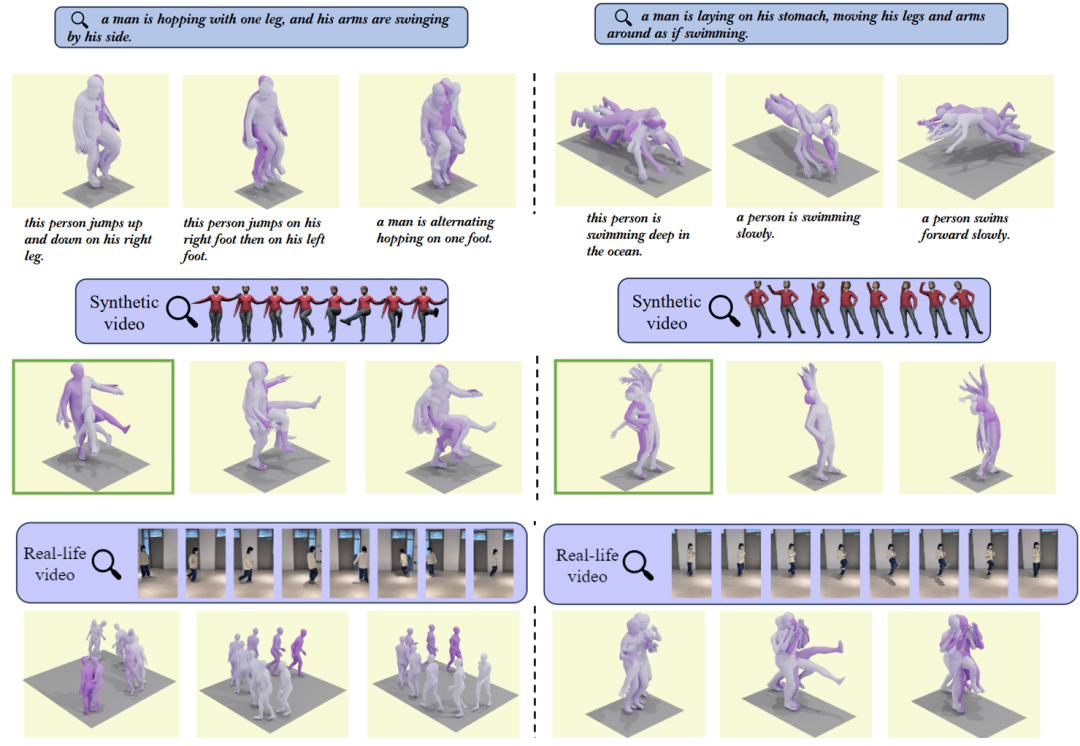
模型效果展示